1. Archipelago¶
1.1. Problem Overview¶
In an IaaS cloud, VM provisioning and destroying happens continiously and it should be fast and efficient. In the same time, VMs should be live-migratable across physical nodes to achieve persistency. So the question boils down to:
How can I deploy VMs from image files in seconds, while in the same time being able to live-migrate them and do that in a large-scale and stable manner?
As far as we know, no one seems to have completely solved the above problem, at least not in the open source world. There are some solutions either proprietary or open source that try to tackle the problem, but all of them seem to have limitations regarding different aspects of the problems.
1.1.1. Proprietary SAN/NAS solutions¶
Proprietary SAN/NAS solutions support live-migration out-of-the-box since the storage is shared across all physical nodes where VMs live. The most advanced ones also support thin cloning and snapshotting, meaning they also solve the ‘fast’ provisioning part. However they have some major problems:
1.1.2. Over the network RAID-1: DRBD¶
DRBD is a great technology. It is open source, proven, mature and if you combine it with a sophisticated virtualization manager that can handle it (such as Google Ganeti) you can also support live VM migrations out-of-the-box, even in geographically distinct locations. DRBD is also very scalable since it is completely decentralized. However it has two big problems:
The above mean that it cannot cater for the ‘fast’ provisioning part and cannot be easily integrated to act as a backend for files, images or objects.
1.1.3. Open source distributed filesystems¶
Open source distributed filesystems seem to be the way to go in the cloud and are highly appreciated and praised by many promiment members of the cloud community. Solutions like Ceph, GlusterFS, MooseFS, ZFS and others are potential candidates when it comes to backing a large scale cloud service. A distributed filesystem is visible by all physical nodes hosting VMs, so live-migration is supported and they can also be used to store files and images. However, such solutions seem to have problems too, when it comes to deploying in a large scale critical environmet. The major ones are:
Our experience also indicates that a cloud platform doesn’t really need filesystem semantics, but rather block and object interfaces. Thus, a distributed filesystem adds complexity and overhead to the picture. The Ceph project seems to be doing a good job towards this direction, but it is still very early to point it as the possible solution.
1.1.4. Multiple storage technologies¶
Since there is no single solution to fit the cloud case, one even more important problem arises. What happens with legacy hardware, how does one maintain, upgrade, move from one technology to the other, or even integrate different storage technologies to cater for different needs in a unified way? And why does a reliable, redundant, scalable data store has to interfere with cloud semantics, clones, snapshots, deduplication, block and file interfaces?
The above problems, which were the ones we also bumped on and tried to solve on our own real-world use case, led us to the design and implementation of Archipelago.
1.2. Archipelago Overview¶
Archipelago is a distinct storage layer that provides the logic and interfaces needed to integrate with a cloud platform, while in the same time being agnostic to the underlying storage technology, which is used to store the actual data.
In the figure below, we see Archipelago running in a number of physical nodes. It provides different endpoints for volume access by VMs or file access via HTTP:
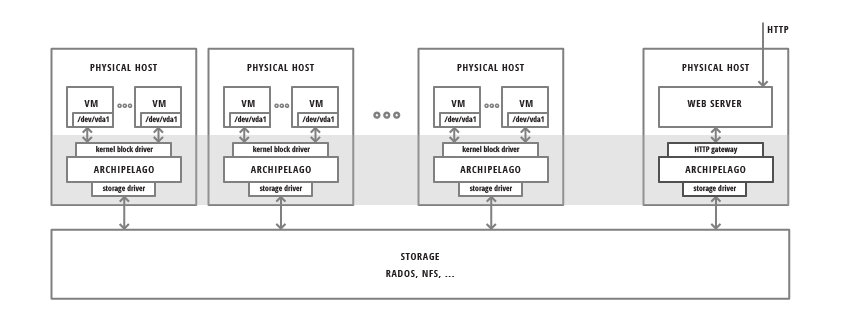
It also provides the corresponding logic for thin volume cloning and snapshotting independently from the actual storage. Archipelago is deployed on each node where the volume will be used (e.g.: acting as a VM disk). The volume is exposed as an independent block device and accessed as such. The data of each volume can reside on any supported underlying storage type. The software stack will take care of any coordination or concurrency control needed between other nodes running Archipelago.
In the same way Archipelago may be deployed on a node that will act as an HTTP gateway for files. It will then provide the corresponding endpoint and the deduplication logic to export the data stored on the underlying storage as files.
Archipelago’s goal is to decouple the composition/snapshot/cloning/deduplicating logic from the storage backend used. Essentially, provide the necessary layer where the aforementioned logic and volume handling is implemented and also implement an interface with pluggable storage drivers, to operate over different storage types. Finally, export different access endpoints for use by the upper layers.
1.3. Idea¶
Every Volume inside a VM can be thought of as a linearly addressable set of fixed-size blocks. The storage of the actual blocks is orthogonal to the task of exposing a single block device for use by each VM. Bridging the gap between the VMs performing random access to Volumes and the storage of actual blocks is Archipelago: a custom storage handling layer which handled volumes as set of distinct blocks in the backend, a process we call volume composition.
For the actual storage of blocks, Archipelago is agnostic to the storage backend used. Through pluggable storage drivers, Archipelago can support multiple storage backends to suit the needs of each deployment. We currently provide two storage drivers. One for simple files, where each object is stored as a single file on the (shared) filesystem, and one for objects backed by RADOS. RADOS is the distributed object store which supports the Ceph parallel filesystem. With RADOS, we can solve the problem of reliable, fault-tolerant object storage through replication on multiple storage nodes.
As mentioned before, Archipelago composes the volume through individual blocks. This is accomplished by maintaining a map for each volume, to map offset in a volume with a single object. The exact offset inside the object, is calculated statically from the fixed object size and the offset in the volume. But having this map and the composition subsystems, allow us to do much more than simple volume composition. Archipelago offers Copy-On-Write snapshottable volumes. Furthermore, each snapshot can be hashed, to allow deduplication to play its part, reducing the storage cost of each hashed object. Furthermore, Archipelago can integrate with Pithos, and use Pithos images to provision a volume with Copy-On-Write semantics (i.e. a clone). Since Pithos images are already hashed, we can store Archipelago hashed volumes, which are indistinguishable from a Pithos image, along with the Pithos images, to enable further deduplication, or even registering an archipelago hashed snapshot as Pithos image file.
Archipelago is used by Cyclades and Ganeti for fast VM provisioning based on CoW volumes. Moreover, it enables live migration of thinly-provisioned VMs with no physically shared storage.
1.4. Endpoint and Backend drivers¶
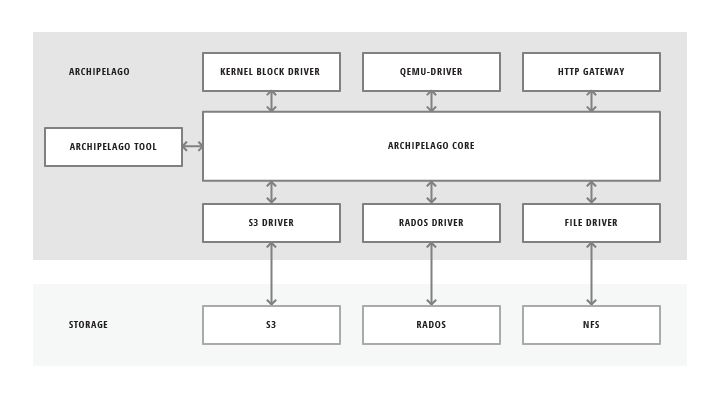
Archipelago allows users to manage and access the underlying data, which is backed by various storage types. In order to do that, Archipelago can provide multiple endpoints for the user or upper layers to interact. Some of them are:
- block device driver
- qemu driver
- user provided process
- command line tool
- http gateway for files
It also implements different drivers to interact with different types of underlying storage technologies.
1.5. Internal Architecture¶
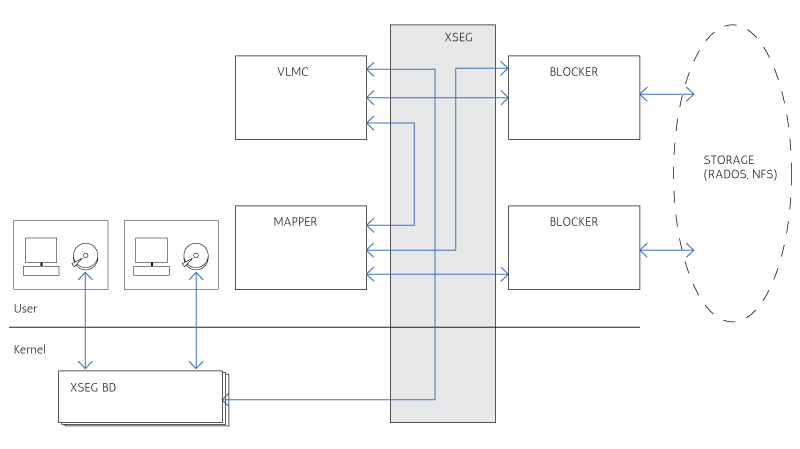
Archipelago consists of several components, both userspace and kernelspace, which communicate through a custom-built shared memory segment communication mechanism. This mechanism, which is called XSEG, also defines a common communication protocol between these components and is provided by the library libxseg. Each Archipelago component, which can be a kernelspace block driver or a userspace process, is an xseg peer. The segment provides ports, where each peer binds. The peer then uses the port to communicate with the other peers on the same segment. The communication consists of requests that are submitted to the receiver port, and are responded to the submitter port.
This form of communication, allows us to develop distinct components for each operation of Archipelago, while being able to communicate with exactly the same protocol between these components, independently from their domain (userspace or kernelspace).
1.5.1. Archipelago components¶
Each Archipelago component serves a distinct purpose and coordinates with the other components to provide the final service.
These components are described below.
1.5.1.1. Volume composer (vlmcd)¶
Volume composer is responsible for the volume composition. Blktap devices direct I/O requests on the volume, to the volume composer. Volume composer then consults the mapper, to get the actual objects on which it will perform the appropriate I/O. It then directs I/O requests for each individual object to the blocker and wait for their completion. In the end, it composes the individual responses, to respond to the original volume request from blktap.
1.5.1.2. Mapper (mapperd)¶
Mapper is responsible for keeping and updating the mappings from volume offsets to individual objects which actually hold the data. It is also responsible for creating new volumes, snapshotting existing ones and create new volume based on a previously captured snapshot (clones). It stores the mappings to the storage backend, from which it reads and/or updates them, keeping them cached when appropriate. It also ensure that each action on the volumes, does not happen unless the necessary volume locks are acquired.
1.5.1.3. File blocker (filed)¶
File blocker is responsible for storing each object as a single file in a specified directory. It servers the requests for each objects as they come from the volume composer and the mapper components.
1.5.1.4. Rados blocker (sosd)¶
Rados blocker is another form of blocker which stores each objects as a single object in a RADOS pool. It can be used instead of the file blocker, to create and use disks over RADOS storage.
1.5.1.5. Block devices (blktap)¶
Each volume on Archipelago is exposed as a block device in the system /dev/xen/blktap-2/ directory. These special devices are nothing more than just another peer, which forwards the requests through the shared memory segment, to the volume composer for completion.
In a nutshell, in archipelago, each blktap device communicates through the shared memory segment with the volume composer. Then the volume composer requests the objects on which it should perform the I/O from the mapper. The mapper takes into account all the necessary logic (taking locks etc) and retrieves the mappings from the storage, by requesting the appropriate objects from the blocker responsible to hold the maps. It then performs any copy on write operations needed and returns the mapping to the volume composer. The volume composer then communicates with the blocker responsible for holding the objects where the actual data reside and composes the responses, to respond to the original request.
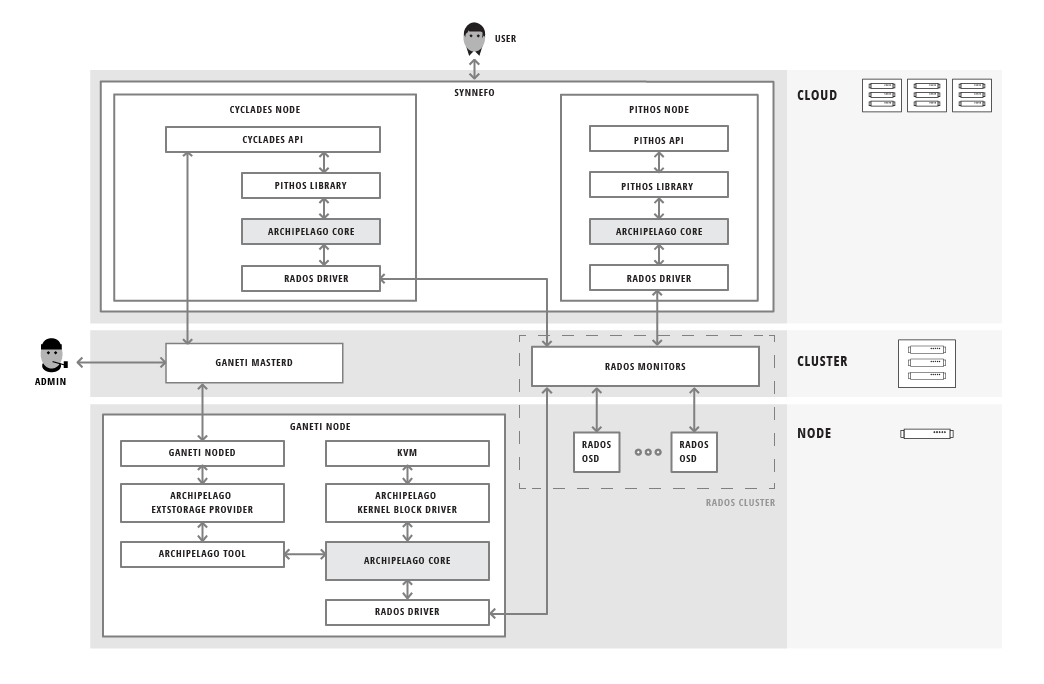
1.6. Archipelago Integration with Synnefo and Ganeti¶
The following figure shows Archipelago, completely integrated with Synnefo and Ganeti in a real-world, large scale cloud environment: